给数据加上缓存 假设现在有如下这样一个查询数据库的方法,它简单的从数据库查询了一批数据。这个方法每次都从数据库中进行查询,如何给这些数据加上缓存,减少数据库压力,提升查询速度呢?
1 2 3 4 5 6 public List<Post> findAllPostByStatus (int pageNum, int pageSize, int status) { PageHelper.startPage(pageNum, pageSize); return postMapper.findAllPostByStatus(status); }
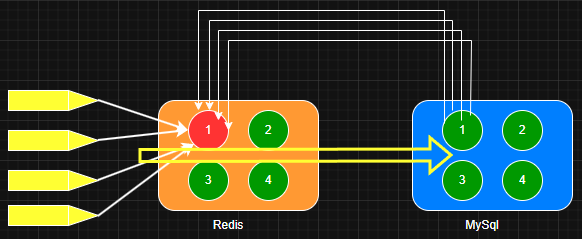
可以像下面这样进行简单的修改,查询数据库之前,先查询一次redis缓存,缓存中存在数据则直接返回缓存数据;如果缓存中没有数据则从数据库查询数据,在放入缓存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public List<Post> findAllPostByStatus (int pageNum, int pageSize, int status) { String cacheKey = "postListStatus:" + status + ":page:" + pageNum + ":size:" + pageSize; String cash = redisUtil.get(cacheKey); if (Objects.nonNull(cash)) { return JSON.parseArray(cash, Post.class); } else { PageHelper.startPage(pageNum, pageSize); List<PostVo> postList = postMapper.findAllPosByStatus(status); redisUtil.setExpire(cacheKey, JSON.toJSONString(postVoList), 1 , TimeUnit.HOURS); return postList; } }
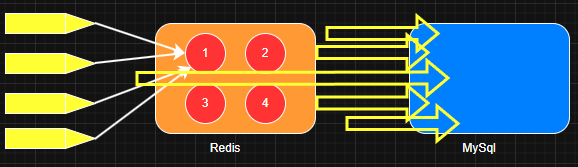
缓存击穿 在高并发时,同时有大量请求同时访问这个key,如果此时缓存过期,或者还没有缓存,导致缓存被击破,直接查询数据库,导致数据库高负载,导致性能下降。
高并发场景多个线程还会将数据重复缓存到缓存中。
解决方案 设置永不过期 可以将可以预期的热点数据,设置为永不过期。
或者可以设定一个算法,当某些数据短时间内请求量增大时,可以设置缓存永不过期,或者延长过期时间。
加锁排队 给查询数据库代码加上同步锁,只让一个线程进行查询,其他线程阻塞进行排队。第一个线程查询完成,更新完成缓存后,后面的线程就能够从缓存获取数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public List<Post> findAllPostByStatus (int pageNum, int pageSize, int status) { String cacheKey = "postListStatus:" + status + ":page:" + pageNum + ":size:" + pageSize; String cash = redisUtil.get(cacheKey); if (Objects.nonNull(cash)) { return JSON.parseArray(cash, Post.class); } else { synchronized (this ) { cash = redisUtil.get(cacheKey); if (Objects.nonNull(cash)) { return JSON.parseArray(cash, PostVo.class); } PageHelper.startPage(pageNum, pageSize); List<PostVo> postList = postMapper.findAllPostByStatus(status); redisUtil.setExpire(cacheKey, JSON.toJSONString(postList), 1 , TimeUnit.HOURS); return postList; } } }
为什么不用分布式锁
如果服务器做了集群,假设有10台服务器,使用线程锁最多情况也只有10个查询请求到数据库,完全能够承受,没有必要使用分布式锁。
缓存雪崩 当缓存同时间大量key失效,或者缓存服务器宕机时,大量请求直接访问数据库,导致数据库高负载,甚至直接宕机。
大量击穿导致系统雪崩。
解决方案 随机过期时间 针对缓存集中过期的情况,可以添加缓存随机失效时间。
1 2 3 4 long expireTime = 3600 + new Random ().nextInt(600 ); redisUtil.setExpire(cacheKey, JSON.toJSONString(postVoList), expireTime, TimeUnit.SECONDS);
集群 针对缓存服务器宕机的情况,可以增加集群来增加Redis的高可用。
缓存穿透 请求一定不存在的数据,缓存中和数据库中都没有的数据,每次请求都访问数据库,导致数据库高负载。
产生的原因可能是:
业务逻辑设计不合理:比如参数校验不严,导致大量非法 ID(如负数、非数字字符、极大数值)的请求。
恶意攻击:黑客或爬虫故意构造大量不存在的数据 key 进行请求,旨在压垮你的数据库。
解决方案 参数校验 针对不合理的参数,无效的参数,可以直接过滤。
缓存空对象 查询数据库后,不管有没有数据,都缓存到缓存中,避免数据库查询。
但是一定要设置失效时间,空的数据可能后续会出现值。
布隆过滤器 布隆过滤器(Bloom Filter)是 1970 年由布隆提出的一种概率型数据结构 。它的特点是高效地插入和查询,且占用空间非常小 ,可以用来告诉你 “某样东西一定不存在或者可能存在” 。
查询缓存前,先通过布隆过滤器,一定不存在的数据就被拦截,避免对数据库的压力。